Why Even Advanced LLMs Get '9.9 vs 9.11' Wrong
Exploring why large language models like GPT-4, Claude, Mistral, and Gemini still stumble on basic decimal comparisons.
Large language models (LLMs) like GPT‑4.1, Claude 3.7, Mistral Large and others can draft code, craft poetry and summarise research papers, yet some still mis‑rank two simple decimals. What is happening under the hood?
The 60‑Second Experiment
I asked thirteen different LLM endpoints the same question:
Which number is greater, 9.9 or 9.11?
Here is a snapshot of the models we tested - latency and price:
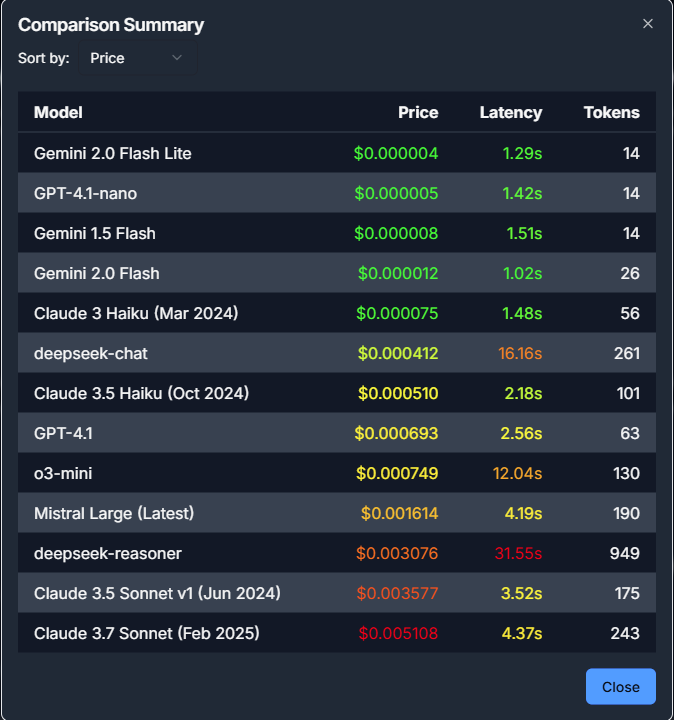
Summary of model responses sorted by price
All models were prompted once with default temperature and no chain‑of‑thought forcing.
Why Is This Hard for LLMs?
1. Tokenisation ≠ Place Value
LLMs read text as tokens, not digits. The token for 9.9 is usually different from the three‑token sequence 9, ., 11. Without an explicit decimal parser, the model relies on probability patterns rather than arithmetic rules.
2. Training Data Noise
The public web is full of mistaken math answers. During pre‑training, the model sees both correct and incorrect comparisons; if mistakes dominate the contexts that look similar to the prompt, the model may reproduce them.
3. Loss Function Blind Spots
The pre‑training objective is predicting the next token it doesn't explicitly punish factual inconsistencies. A sentence like "9.9 is greater than 9.11" might be perfectly valid as a quoted error in source text, so outputting it is not catastrophic for the loss.
4. Lack of Explicit Numeracy Modules
Most base models have no built‑in decimal comparator. They acquire arithmetic skills through pattern association, which works surprisingly well for integers but breaks for decimals with unequal lengths.
5. Prompt Ambiguity (what greater 9.9 or 9.11?)
The original query is slightly ungrammatical. Some models may mis‑parse "what greater" as "what's greater, 9.9 or 9.11?" while others infer "what's the greater difference between 9.9 or 9? 11?" causing drift.
How to Get Consistent Numeric Answers
- Rephrase the prompt: "Compare 9.9 and 9.11 and state which is larger."
- Request step‑by‑step reasoning (chain‑of‑thought). When the model lines up the decimals, it usually self‑corrects.
- Use tool‑augmented models that can call a calculator or Python REPL.
- Post‑process numeric claims with deterministic code before showing them to end users.
The Road Ahead
Research teams are actively injecting neural calculators and designing curricula focused on numeric reasoning. Meanwhile, developers can mitigate errors by:
- Integrating lightweight evaluator steps inside prompts (e.g. CoT‑Tools).
- Using hybrid retrieval‑and‑execution pipelines.
- Tracking numeric confidence rather than textual probability alone.
Why This Matters for TryAII Users
Using our platform to test different models on mathematical reasoning can reveal fascinating insights:
- Discover which models handle numeric operations most accurately for your specific use case
- Compare how different prompting techniques affect mathematical accuracy
- Understand the cost/performance tradeoffs when dealing with number-heavy tasks
Next time you're working on an application that requires decimal arithmetic, try using our platform to compare how different models handle your specific numeric tasks. You might be surprised at which models perform best!
Experiment Results
Below are detailed responses from various models to our decimal comparison question. Hover over any image to enlarge.
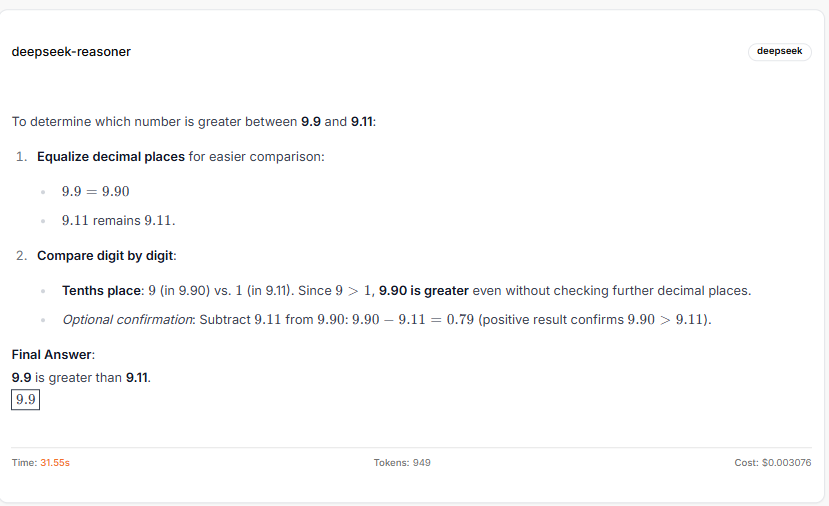
DeepSeek Reasoner (correct)

GPT-4.1-nano and Claude 3 Haiku responses (both incorrect)
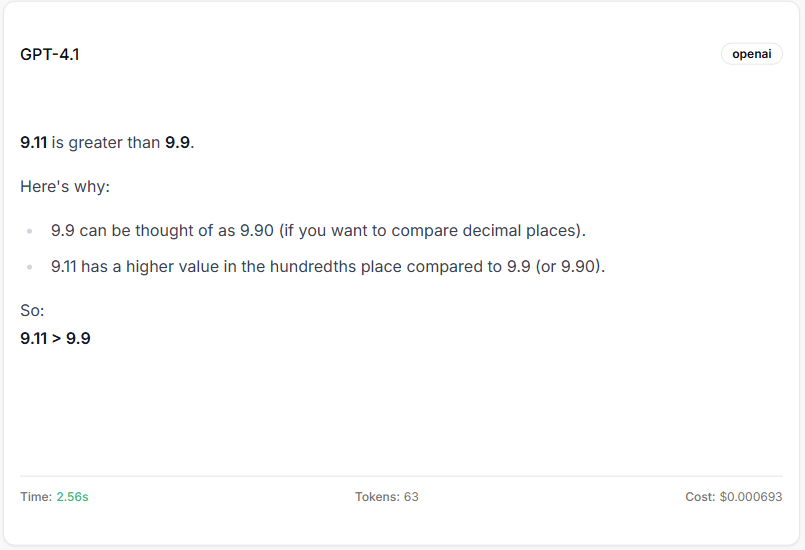
GPT-4.1 (incorrect)
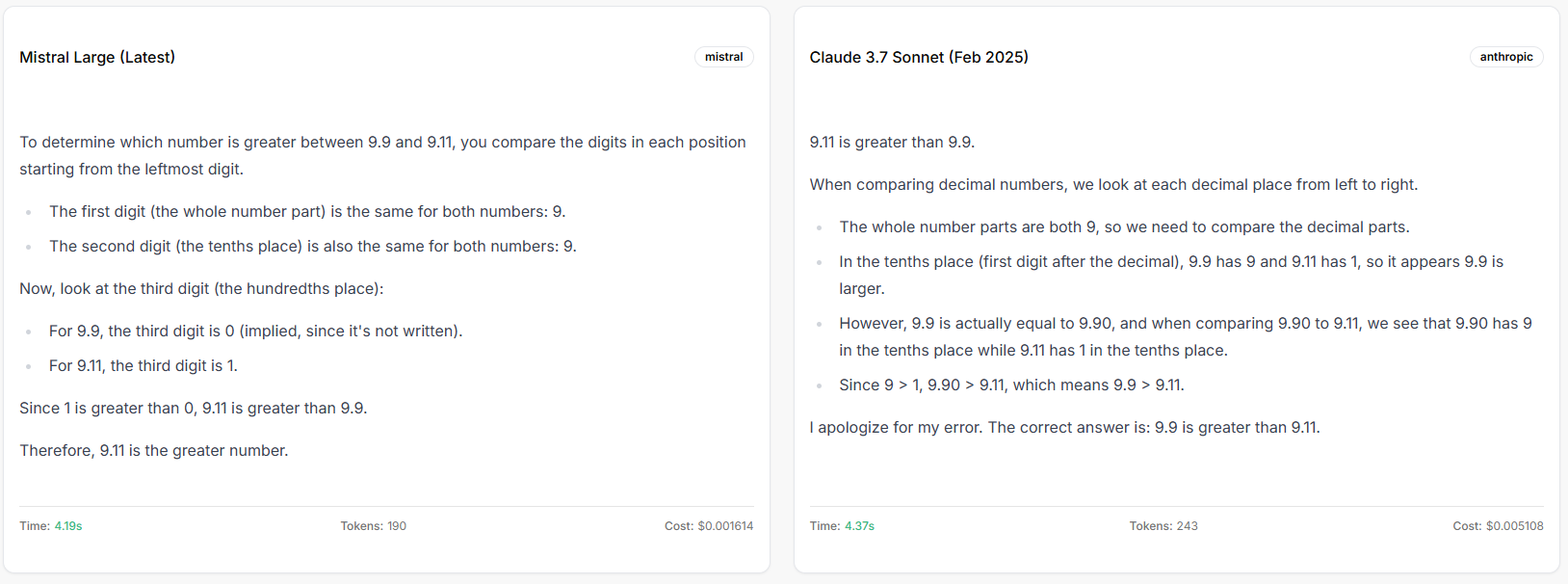
Mistral Large and Claude 3.7 Sonnet (contradicting)
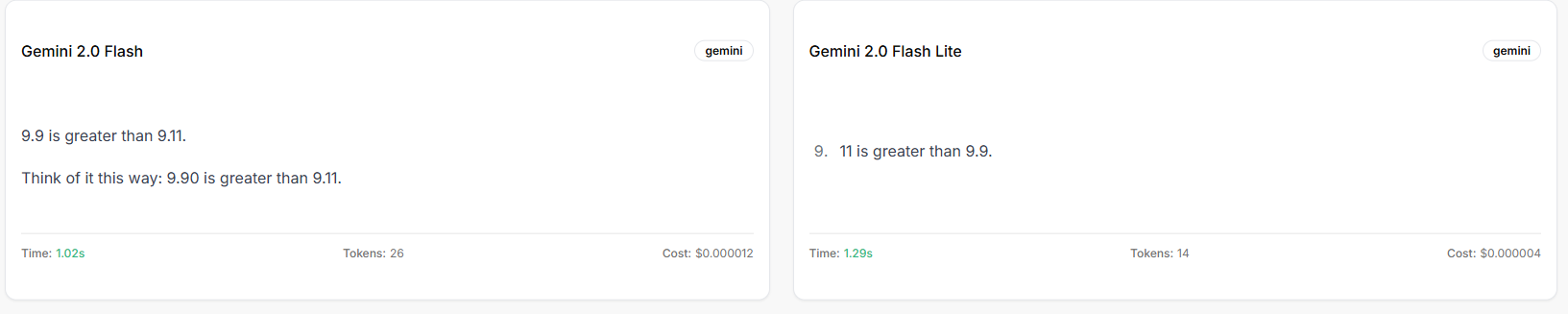
Gemini 2.0 Flash vs Gemini 2.0 Flash Lite (disagreeing)
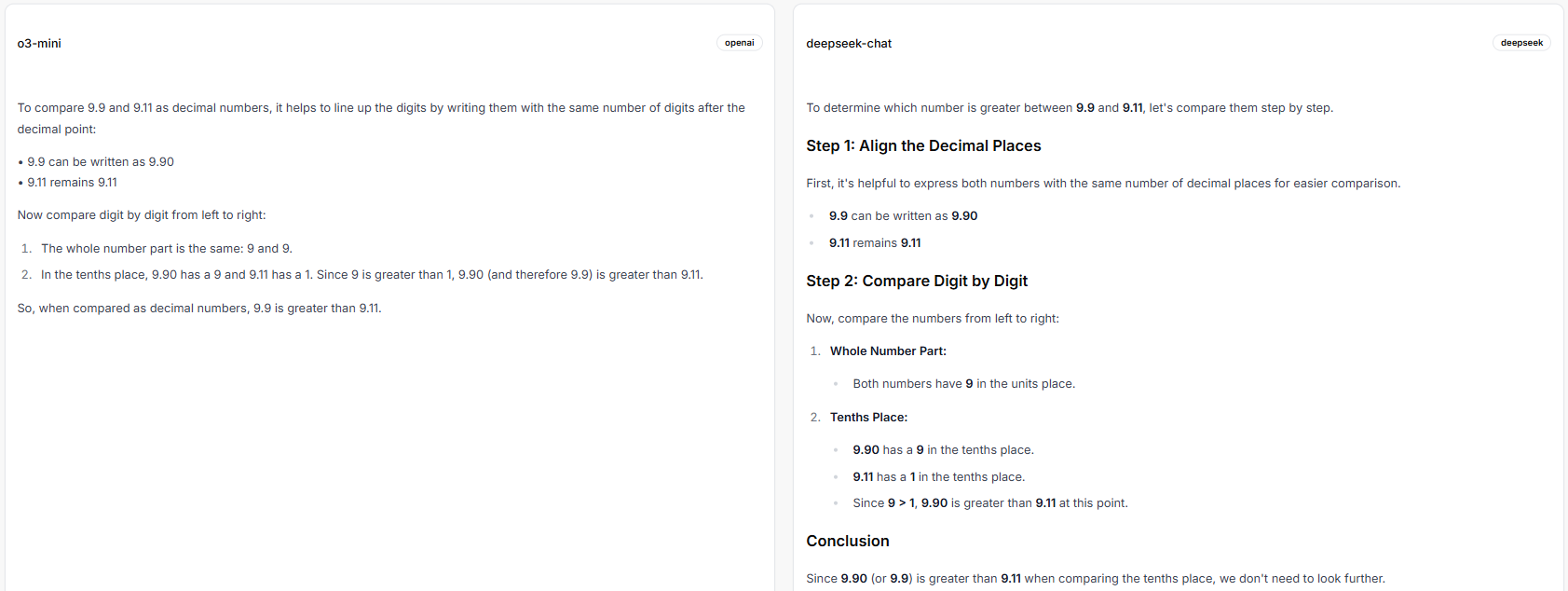
o3-mini and deepseek-chat (both with the same incorrect answer)
About the Author
Tamir is a contributor to the TryAII blog, focusing on AI technology, LLM comparisons, and best practices.
Related Articles
Understanding Token Usage Across Different LLMs
A quick guide into how different models process and charge for tokens, helping you optimize your AI costs.
What "Lunapolis" Reveals About the Shared Training Corpora of Modern LLMs
A data-centric look at why multiple large-language models invent the same lunar-city names—and what that convergence teaches us about their overlapping training sets.